Make3D
Convert your still image into 3D model: Data
State of the art results
Make3D Range Image Data
This dataset contains aligned image and range data:
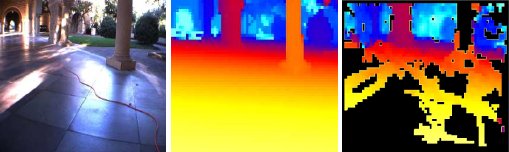
Make3D Image and Laser Depthmap
Image and Laser and Stereo
Image and 1D Laser
Image and Depth for Objects
Video and Depth (coming soon)
Different types of examples are there---outdoor scenes (about 1000), indoor (about 50), synthetic objects (about 7000), etc.
Make3D Laser+Image data(Used in "Learning Depth from Single Monocular Images", NIPS 2005.)
** Email Prof. Saxena in order to submit your results on this list.
Required: Any report or publication using this data should cite its use as: [1] and [2] (dataset 2), or [1] and [3] (dataset 1): |

|
||||||||||||||||||||||||
Stereo+Laser+Image Data
The depths here are raw logs from the laser scanner, in the following ascii format: |
|
||||||||||||||||||||||||
Car Driving 1-d depth data1-D depth data (useful for robotic applications)Use of this data should cite: High Speed Obstacle Avoidance using Monocular Vision and Reinforcement Learning, Jeff Michels, Ashutosh Saxena, Andrew Y. Ng. In ICML 2005. 3-D Depth Reconstruction from a Single Still Image, Ashutosh Saxena, Sung H. Chung, Andrew Y. Ng. In IJCV 2007. |

|
||||||||||||||||||||||||
Depth+Image for synthetic objectsAvailable here.Use of this data should cite: Robotic Grasping of Novel Objects, Ashutosh Saxena, Justin Driemeyer, Justin Kearns, Andrew Ng. In NIPS 19, 2006. Learning to Grasp Novel Objects using Vision, Ashutosh Saxena, Justin Driemeyer, Justin Kearns, Chioma Osondu, Andrew Y. Ng. 10th International Symposium of Experimental Robotics (ISER), 2006. |


|
||||||||||||||||||||||||
Depth+Image for indoors/objectsExternal link to:USF Range Image Database Middlebury data |
Note: Use of this data is free to use, as long as you cite its use in any report, presentation, code, etc. Further, no permissions are obtained from people who might be present in these images; therefore, by downloading these files, you agree not to hold the authors or Stanford University or Cornell University liable for any damage, lawsuits, or other loss resulting from the possession or use of files.